Mise en production d’une application RAG pour la société Adezif avec n8n, Bubble et Supabase
Mise en production de ma première application RAG¶
J’ai consacré cette année beaucoup de temps à la veille et R&D autour des applications d’intelligence artificielle, en particulier sur les RAG (Retrieval Augmented Generation). J’ai déjà partagé des apprentissages de cette veille, notamment dan mon article précédent (Premiers pas avec le Retrieval Augmented Generation (RAG)) ainsi lors d’une conférence sur les systèmes RAG lors de la No-Code Week à Cologne.
Cette veille n’était pas menée aveuglément : je cherchais à répondre à une demande client réelle. Après un certain nombre d’itérations j’ai pu finalement livrer un outil qui entre en production cet été. Je partagerai dans cet article les challenges rencontrés ainsi que les choix d’implémentation pris pour livrer ce projet.
Vous voulez les plans de cette application ?
Je réfléchis actuellement à partager des workflows et applications sous forme de template adaptables. Inscrivez-vous sur la liste d’attente pour être informé lors de la publication de ces templates. Je suis intéressé par les templates
Contexte du projet¶
La société, Adezif, est un acteur majeur dans la fourniture et la transformation de rubans adhésifs et colles techniques. Au-delà des grandes marques du secteur (3M, Loctite, Tesa…), Adezif propose également des produits génériques sous sa propre marque.
Adezif est client de Digi-Studio depuis 2022, avec notamment une application Bubble en production son catalogue produit interne. L’objectif de ce nouveau projet est de développer un assistant IA qui doit s’appuyer sur une base de connaissance non structurée (corpus initial d’environ 1000 fiches techniques et brochures au format PDF, issus de fournisseurs variés). L’assistant doit aider les commerciaux de l’entreprise à trouver des produits adaptés à partir d’une description d’un besoin client.
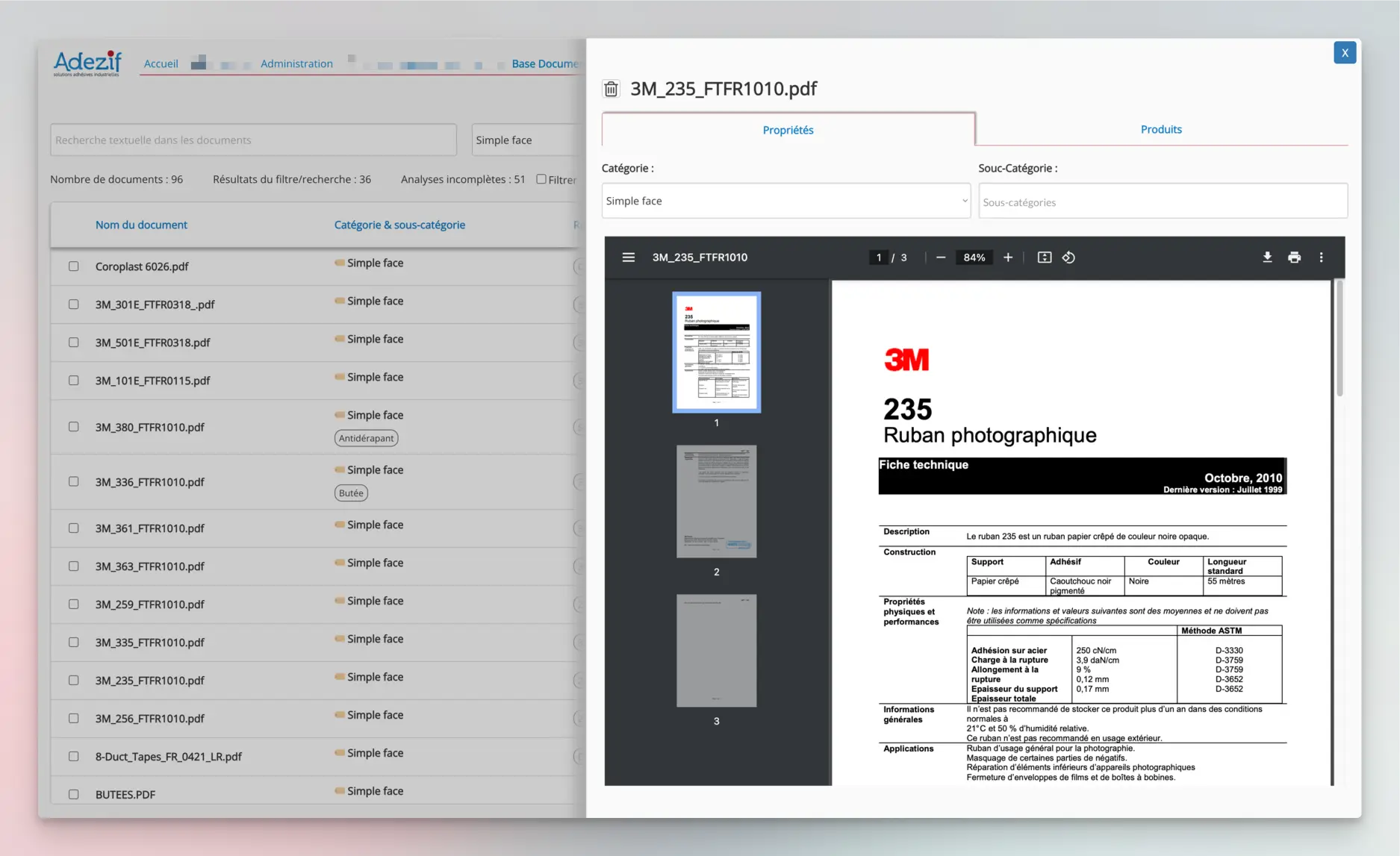
C’est en essayant de paramétrer un GPT dédié que j’ai constaté les limites du concept dans ce cas de figure : les réponses du GPT était décevantes et son fonctionnement une boîte noire : impossible comprendre comment la recherche documentaire opérait et pourquoi les résultats n’étaient pas au rendez-vous.
J’ai donc décidé de m’intéresser aux RAG pour voir si je pouvais obtenir de meilleurs résultats en ayant la main sur les différents paramètres du système.
Rappel des principes des RAG¶
Le Retrieval Augmented Generation (RAG) est un ensemble de techniques qui permettent d’augmenter les capacités d’un LLM en lui attachant une base de connaissance externe.
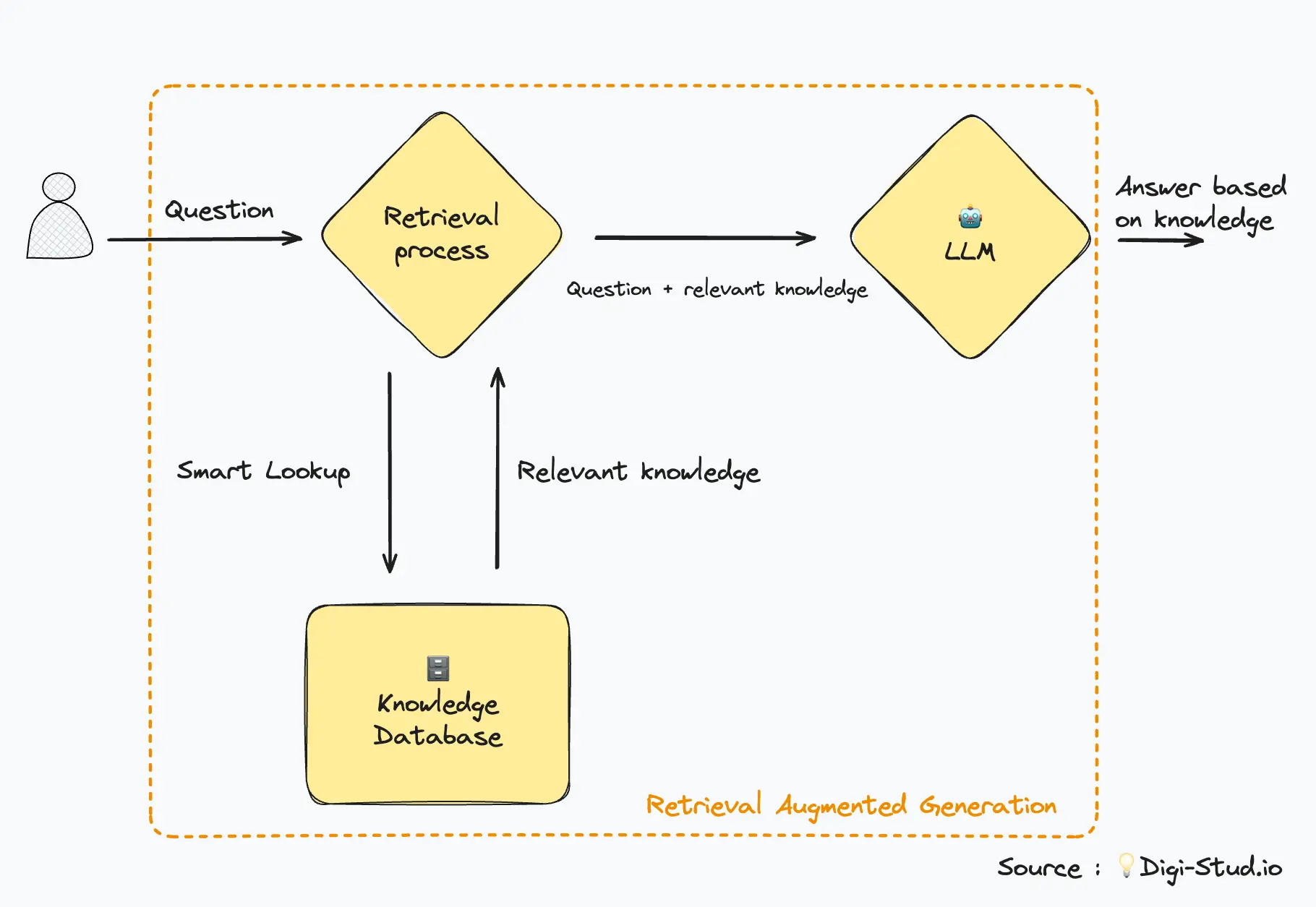
Pour la recherche “intelligente” dans la base de connaissance, on utilise la recherche par similarité qui repose sur les embeddings. Pour plus de détail sur ces techniques, vous pouvez vous reporter deux articles cités en introduction.
Principales difficultés¶
La conception d’un RAG dans ce contexte présenté deux principales difficultés :
- Nature des données : Les systèmes RAG sont généralement bien adaptés pour une base de connaissances avec des données sémantiques riches. Ils sont cependant moins performants pour des listes de paramètres techniques, des grandeurs physiques avec des valeurs numériques associées. Or ces caractéristiques techniques représentent une partie importante de l’information qui nous intéresse dans ce projet.
- Architecture technique : Il était logique de greffer cette nouvelle fonctionnalité sur l’application Bubble existantes. Toutefois, Bubble ne propose de base de donnée vectorielle indispensable pour un système RAG (pour les embeddings). Il a donc été nécessaire de construire une architecture hybride Bubble / Supabase (vector database).
Solution développée¶
Pour tenir compte de ces particularités, l’application développée repose sur 3 principales fonctionnalités :
- Pre-processing des données
- Recherche traditionnelle
- RAG
Voyons chaque étape en détail.
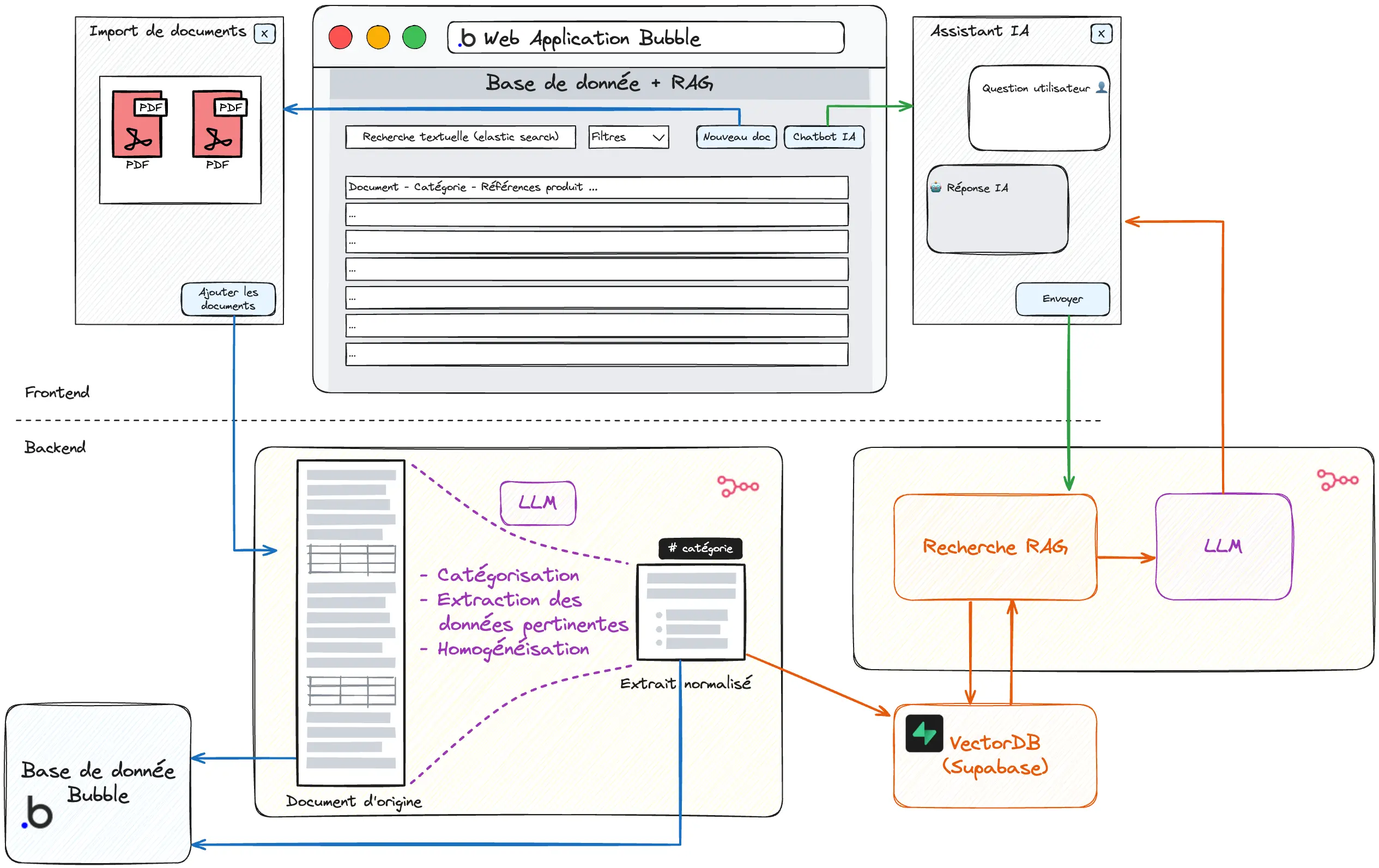
1. “Pre-processing” lors de l’ajout des documents¶
Lors de l’ajout d’un nouveau document (PDF), plusieurs actions sont réalisées automatiquement :
- Le contenu du PDF est extrait et indexé à l’identique dans la base de donnée Bubble. C’est ce qui permettra la recherche “traditionnelle” (recherche textuelle). Le document d’origine (PDF) est également stocké et consultable via la base de donnée Bubble.
- Le document est catégorisé automatiquement. Cette catégorisation facilitera la recherche et permettra d’orienter les traitements ultérieurs.
- Un traitement IA est appliqué pour extraire et nettoyer le contenu pertinent (en tenant compte de la catégorie du document). C’est cette donnée qui alimentera la base de connaissance du RAG.
- Le contenu traité est indexé dans la base de donnée vectorielle (Supabase). La base de donnée Supabase et la base de donnée Bubble partagent un identifiant commun pour demeurer alignées dans la durée.
2. Recherche traditionnelle¶
Des filtres par catégorie et une recherche textuelle (“elastic search” pour une recherche approximative) permettent de parcourir les documents de manière traditionnelle, sans utiliser d’agent IA. Cette première fonctionnalité apporte déjà une amélioration par rapport à la situation initiale où les documents PDF étaient simplement stockés sur un lecteur réseau partagé.
3. RAG¶
Il est possible enfin d’utiliser un agent IA pour répondre à des questions techniques sur les produits indexés. Plusieurs particularités permettent d’augmenter la pertinence de la recherche RAG
- Le RAG s’appuie sur la donnée traitée (phase de pre-processing) et non sur la donnée brute
- Les filtres utilisateurs peuvent être pris en compte pour réduire le scope de recherche (catégories, recherche…)
- La recherche combine une recherche par similarité et une recherche par mots clés (on parle de “hybrid search”).
La fonctionnalité RAG est développée sur n8n et connectée à l’application Bubble. Grâce aux nodes LangChain propoposés par n8n il est facile de comparer les différents modèles de LLM (OpenAI, Anthropic, Mistral…).
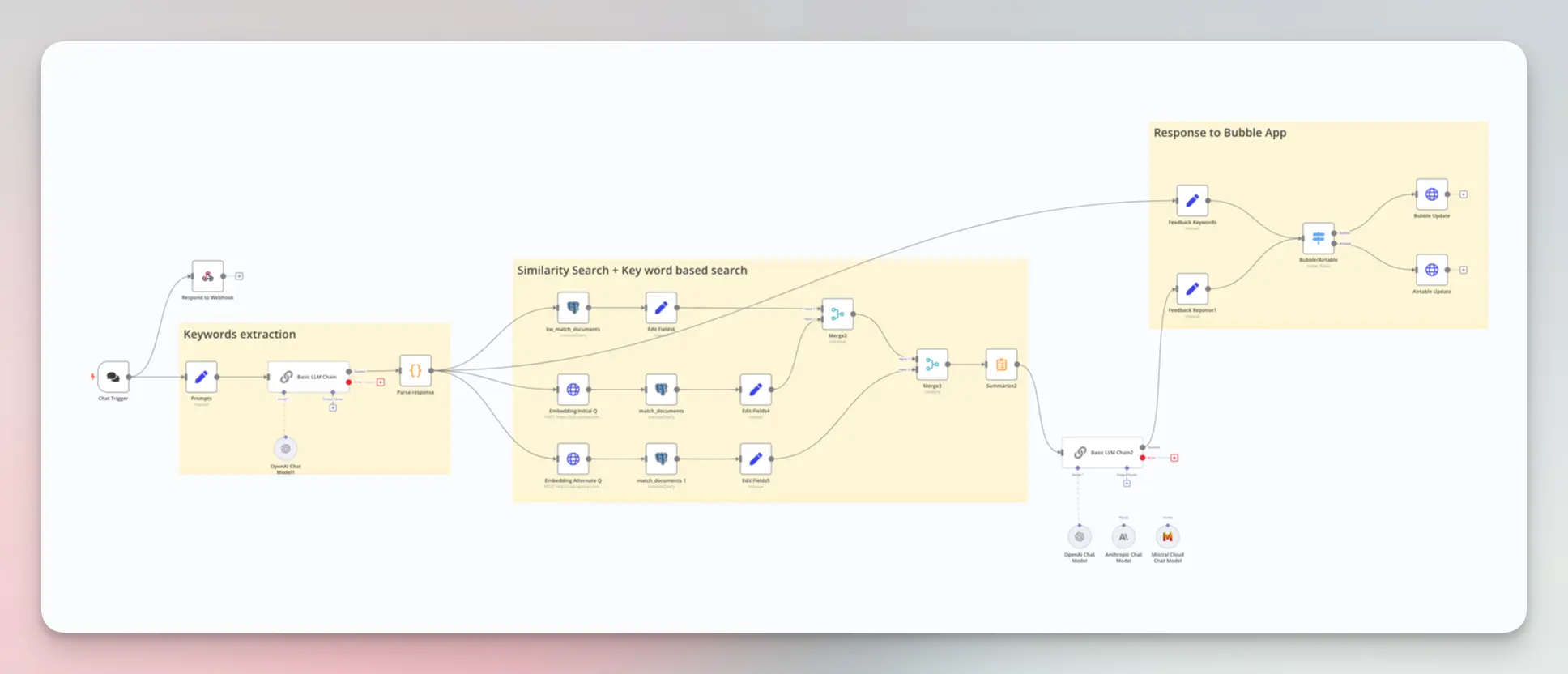
Résultats¶
Le traitement de la donnée lors de l’ingestion des documents ainsi que l’incitation de l’utilisateur à préciser le scope de sa question permettent d’augmenter sensiblement la pertinence des réponses produites par l’assistant IA.
Par ailleurs, l’outil est présenté en premier lieu comme un outil de recherche documentaire traditionnel (filtres, recherche textuelle, consultation des documents originaux en pdf) et non comme un unique chatbot IA. Cela permet de faciliter l’adoption du produit grâce à des concepts plus familiers dans lesquels l’IA apporte un angle d’approche supplémentaire sans être une fin en soi.
Pour conclure sur les RAG :
- Il vaut mieux limiter au maximum le scope de l’application pour avoir des résultats pertinents plutôt que d’essayer de faire un système tout-en-un
- Le nettoyage et l’homogénéisation de la donnée d’entrée reste une étape au moins aussi importante que les techniques de recherche et de prompt engineering
- L’IA ne doit pas être une fin en soit, mais doit venir apporter une valeur et un confort supplémentaire.
Vous voulez les plans de cette application ?
Je réfléchis actuellement à partager des workflows et applications sous forme de template adaptables. Inscrivez-vous sur la liste d’attente pour être informé lors de la publication de ces templates. Je suis intéressé par les templates